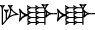
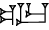Tibaren писал(а):apshu писал(а):
Ok, давайте. Хотите выложу шумерский сводеш? не найдете нигде - а
А ну ка давайте, очень интересно??!!
Выкладываю :)
Вот: сводеш делал сам - пару лет назад, извиняюсь за ошибки -почти не проверял по епсд
по просьбе своего армянского друга сравнил с армянским - увы...
сходства почти нет, но чтобы его успокоить, и чтобы не обольщались другие гордые народы, скажу, что у остальных еще хуже

(если серьезно, по шумерским меркам, схожесть немалая(!)) но армянский решил не убирать (просто сразу и не смог убрать - в моем макбуке маковский же exel-даже не получилось удалить столбец (!!!)- подумал - и к лучшему)- может кто поправит арм. часть (или подгонит, т.е.
найдет искусственно более близкие синонимы, что
очень интересно).
PS. поправьте и шумерский - не обижусь. И сравните со своими языками
арм. сводеш брал из интернета
eng a r m ---------- sumerian
1 I ես es [jɛs] ĝae
2 you (singular) դու du [du] zae
3 he նա na [nɑ] ane
4 we մենք menk' [mɛnkʰ] menden
5 you (plural) դուք duk' [dukʰ] menzen
6 they նրանք nrank' [nəˈɾɑnkʰ] anene
7 this այս ays [ɑjs] nen
8 that այն ayn [ɑjn] agin
9 here այստեղ aysteġ [ɑjsˈtɛʁ] gu'e
10 there այնտեղ aynteġ [ɑjnˈtɛʁ] ĝal
11 who ով ov [ov] aba
12 what ինչ inč [inʧʰ] ana
13 where որտեղ, ուր orteġ, ur [voɾˈtɛʁ], [uɾ] ma'ur
14 when երբ erb [jɛɾpʰ] menam
15 how ինչպես inčpes [inʧʰˈpɛs] agin
16 not ոչ, չ- oč, č- [voʧʰ], [ʧʰ] nu
17 all բոլոր bolor [boˈloɾ] du
18 many շատ šat [ʃɑt] šar
19 some որոշ oroš [voˈɾoʃ] ni
20 few քիչ k'ič [kʰiʧʰ]
21 other այլ, ուրիշ ayl, uriš [ɑjl], [uˈɾiʃ]
22 one մեկ mek [mɛk] aš
23 two երկու erku [jɛɾˈku] min
24 three երեք erek [jɛˈɾɛkʰ] eš
25 four չորս čors [ʧʰoɾs] limmu
26 five հինգ hing [hing] ya
27 big մեծ meç [mɛʦ] mah
28 long երկար erkar [jɛɾˈkɑɾ] gid
29 wide լայն layn [lɑjn] barag
30 thick հաստ hast [hɑst] gur
31 heavy ծանր çanr [ʦɑˈnəɾ] idim
32 small փոքր p'ok'r [pʰoˈkʰəɾ] tur
33 short կարճ karč̣ [kɑɾʧ] lugud
34 narrow նեղ neġ [nɛʁ] hulu
35 thin բարակ barak [bɑˈɾɑk] sal
36 woman կին kin [kin] munus
37 man (adult male) տղամարդ tġamard [təʁɑˈmɑɾtʰ] ili
38 man (human being) մարդ mard [mɑɾtʰ] lulu
39 child երեխա erexa [jɛɾɛˈχɑ] a'e
40 wife կին kin [kin] dam
41 husband ամուսին amusin [ɑmuˈsin] namĝitlam
42 mother մայր mayr [majɾ] ama
43 father հայր hayr [hɑjɾ] abba
44 animal կենդանի kendani [kɛntʰɑˈni] kyndar
45 fish ձուկ juk [ʣuk] zum
46 bird թռչուն t'ṙčun [tʰərˈʧʰun] ti'uz
47 ерунда շուն šun [ʃun] ur
48 louse ոջիլ oǰil [voˈʧʰil] mar
49 snake օձ òj [oʦʰ] ah
50 worm ճիճու č̣ič̣u [ʧiˈʧu]
51 tree ծառ çaṙ [ʦɑr] urana
52 forest անտառ antaṙ [ɑnˈtɑr] tir
53 stick փայտ p'ayt [pʰɑjt] unu
54 fruit պտուղ ptuġ [pəˈtuʁ] mudum
55 seed սերմ serm [seɾm] apin
56 leaf տերև terev [tɛˈɾɛv] emeEŠUŠ
57 root արմատ armat [ɑɾˈmɑt] arina
58 bark (of a tree) կեղև keġev [kɛˈʁɛv] ĝešbargana
59 flower ծաղիկ çaġik [ʦɑˈʁik] girim
60 grass խոտ xot [χot] HARran
61 rope պարան paran [pɑˈɾɑn] eš
62 skin մաշկ, կաշի mašk, kaši [mɑʃk], [kɑˈʃi] kuš
63 meat միս mis [mis] niĝšuma
64 blood արյուն aryun [ɑɾˈjun] urin
65 bone ոսկոր oskor [vosˈkoɾ]
66 fat (noun) ճարպ č̣arp [ʧɑɾp] lib
67 egg ձու ju [ʣu] zuzu
68 horn եղջյուր, պոզ eġǰyur, poz [jɛʁˈʤjuɾ], [poz] u
69 tail պոչ poč [poʧʰ] andaĝal
70 feather փետուր p'etur [pʰɛˈtuɾ]
71 hair մազ maz [mɑz] dilib
72 head գլուխ glux [gəˈluχ] saĝ
73 ear ականջ akanǰ [ɑˈkɑnʤ] ĝeštug
74 eye աչք ačk' [ɑʧʰkʰ] igi
75 nose քիթ k'it [kʰitʰ] kiri
76 mouth բերան beran [bɛˈɾɑn] kag
77 tooth ատամ atam [ɑˈtɑm] zu
78 tongue (organ) լեզու lezu [lɛˈzu] eme
79 fingernail եղունգ eġung [jɛˈʁung] umbin
80 foot ոտք otk' [votkʰ] ĝiri
81 leg ոտք otk' [votkʰ] bad
82 knee ծունկ çunk [ʦunk] dub
83 hand ձեռք jerk' [ʣɛrkʰ] šu
84 wing թև t'ev [tʰɛv] pamušenak
85 belly փոր p'or [pʰoɾ] hašbar
86 guts փորոտիք, աղիք p'orotik', aġik' [pʰoɾoˈtikʰ], [ɑˈʁikʰ]
87 neck վիզ viz [viz] gu
88 back մեջք meǰk' [meʧʰkʰ] ma'egir murgu
89 breast կուրծք kurçk' [kuɾʦkʰ] ubur
90 heart սիրտ sirt [siɾt] gakkul
91 liver լյարդ lyard [ljɑrtʰ] bar
92 to drink խմել xmel [χəˈmɛl] anaĝ
93 to eat ուտել utel [uˈtɛl] gu
94 to bite կծել kçel [kəˈʦɛl] zu du
95 to suck ծծել ççel [ʦəˈʦɛl] sub
96 to spit թքել t'k'el [tʰəˈkʰɛl]
97 to vomit ործկալ orçkal [voɾʦˈkɑl]
98 to blow փչել p'čel [pʰəˈʧʰɛl] bul
99 to breathe շնչել šnčel [ʃənˈʧʰɛl] paĝ
100 to laugh ծիծաղել çiçaġel [ʦiʦɑˈʁɛl] isiš
101 to see տեսնել tesnel [tɛsˈnɛl] igi sig
102 to hear լսել lsel [ləˈsɛl] ĝeš tuku
103 to know իմանալ, գիտենալ imanal, gitenal [imɑˈnɑl], [gitɛˈnɑl] zu
104 to think մտածել mtaçel [mətɑˈʦɛl] šag dab
105 to smell հոտ զգալ hot zgal [hot əzˈgɑl] sim
106 to fear վախենալ vaxenal [vɑχɛˈnɑl] buluh
107 to sleep քնել k'nel [kʰəˈnɛl] u ku
108 to live ապրել aprel [ɑpˈɾɛl] lug
109 to die մեռնել meṙnel [mɛrˈnɛl] ug
110 to kill սպանել spanel [spɑˈnɛl] gaz
111 to fight կռվել kṙvel [kərˈvɛl] ada
112 to hunt որսալ orsal [voɾˈsɑl] ešla
113 to hit խփել, հարվածել xp'el, harvaçel [χəˈpʰɛl], [hɑɾvɑˈʦɛl] du
114 to cut կտրել ktrel [kətˈɾɛl] bur
115 to split բաժանել bažanel [bɑʒɑˈnɛl] bar
116 to stab խոցել xoc'el [χoˈʦʰɛl]
117 to scratch քերծել, քորել k'erçel, k'orel [kʰɛɾˈʦɛl], [kʰoˈɾɛl] ki hur
118 to dig փորել p'orel [pʰoˈɾɛl] bal
119 to swim լողալ loġal [loˈʁɑl]
120 to fly թռչել t'ṙčel [tərˈʧʰɛl] baraš
121 to walk քայլել k'aylel [kʰɑjˈlɛl] a sud
122 to come գալ gal [gɑl] andaĝal
123 to lie (as in a bed) պառկել paṙkel [pɑrˈkɛl] eme sig gu
124 to sit նստել nstel [nəsˈtɛl] dur
125 to stand կանգնել kangnel [kɑngˈnɛl] gub
126 to turn (intransitive) շրջվել šrǰvel [ʃəɾʤˈvɛl] lug
127 to fall ընկնել ënknel [ənkˈnɛl] dirig
128 to give տալ tal [tɑl] a ru
129 to hold պահել, բռնել pahel,bṙnel [pɑˈhɛl], [bərˈnɛl] haza
130 to squeeze սեղմել seġmel [sɛχˈmɛl] hehezer
131 to rub շփել šp'el [ʃəˈpʰɛl] sub
132 to wash լվալ lval [ləˈvɑl] a tu
133 to wipe սրբել srbel [səɾˈpʰɛl] šu gur
134 to pull ձգել, քաշել jgel, k'ašel [ʣəˈkʰɛl], [kʰɑˈʃɛl] haš gid
135 to push հրել hrel [həˈɾɛl] du
136 to throw նետել netel [nɛˈtɛl] gurud
137 to tie կապել kapel [kɑˈpɛl] dimgal
138 to sew կարել karel [kɑˈɾɛl] bulug
139 to count հաշվել hašvel [hɑʃˈvɛl] šid
140 to say ասել asel [ɑˈsɛl] gu de
141 to sing երգել ergel [jɛɾˈkʰɛl] šir
142 to play խաղալ xaġal [χɑˈʁɑl] enedi
143 to float լողալ loġal [loˈʁɑl] dirig
144 to flow հոսել hosel [hoˈsɛl] gen
145 to freeze սառչել saṙčel [sɑrˈʧʰɛl]
146 to swell ուռել uṙel [uˈrɛl] ul
147 sun արև arev [ɑˈɾɛv] ud
148 moon լուսին lusin [luˈsin] itud
149 star աստղ astġ [ɑsˈtəʁ] mulan
150 water ջուր ǰur [ʤuɾ] a
151 rain անձրև anjrev [ɑnˈʣɾɛv] im
152 river գետ get [gɛt] id
153 lake լիճ lič̣ [liʧ]
154 sea ծով çov [ʦov] ab
155 salt աղ aġ [ɑʁ] arazum, mun
156 stone քար k'ar [kʰɑɾ] har
157 sand ավազ avaz [ɑˈvɑz] imanak
158 dust փոշի p'oši [pʰoˈʃi] sahar
159 earth հող hoġ [hoʁ] u
160 cloud ամպ amp [ɑmp] dungu
161 fog մառախուղ, մշուշ maṙaxuġ, mšuš [mɑrɑˈχuʁ], [məˈʃuʃ] muru
162 sky երկինք erkink' [jɛɾˈkinkʰ] an
163 wind քամի k'ami [kʰɑˈmi] tumu
164 snow ձյուն jyun [ʣjun] kuš
165 ice սառույց saṙuyc' [sɑˈrujʦʰ] amagi
166 smoke ծուխ çux [ʦuχ] sar
167 fire հուր, կրակ hur, krak [huɾ], [kəˈɾɑk] urnim
168 ash մոխիր moxir [moˈχiɾ] didal
169 to burn վառվել, այրվել vaṙvel, ayrvel [vɑrˈvel], [ɑjɾˈvɛl] bar
170 road ճամփա, ճանապարհ č̣amp'a, č̣anaparh [ʧɑmˈpʰɑ], [ʧɑnɑˈpɑɾ] kaska
171 mountain լեռ, սար leṙ, sar [lɛr], [sɑɾ] kur
172 red կարմիր karmir [kɑɾˈmiɾ] dara
173 green կանաչ kanač [kɑˈnɑʧʰ] sissi
174 yellow դեղին deġin [dɛˈʁin] nisig
175 white սպիտակ spitak [spiˈtɑk] babbar
176 black սև sev [sɛv] giggi
177 night գիշեր gišer [giˈʃɛɾ] gi
178 day օր òr [oɾ] ud
179 year տարի tari [tɑˈɾi] mu
180 warm տաք tak' [tɑkʰ]
181 cold ցուրտ c'urt [ʦʰuɾt] eš
182 full լիքը lik'ë [liˈkʰə] lum
183 new նոր nor [noɾ] gibil
184 old հին hin [hin] libir
185 good լավ lav [lɑv] dug
186 bad վատ vat [vɑt] hulu
187 rotten փտած p'taç [pʰəˈtɑʦ] huldim
188 dirty կեղտոտ keġtot [kɛχˈtot] mudur
189 straight ուղիղ uġiġ [uˈʁiʁ] si sa
190 round կլոր klor [kəˈloɾ] šu niĝin
191 sharp (as a knife) սուր sur [suɾ] kizurra
192 dull (as a knife) բութ but' [butʰ]
193 smooth հարթ hart' [hɑɾtʰ]
194 wet թաց t'ac' [tʰɑʦʰ] duru
195 dry չոր čor [ʧʰoɾ] ah
196 correct ճիշտ č̣išt [ʧiʃt] šušur
197 near մոտ mot [mot] teĝ
198 far հեռու heṙu [hɛˈru] asilal
199 right աջ aǰ [ɑʧʰ] zid
200 left ձախ jax [ʣɑχ] gab
201 at -ում, -ին -um, -in [um], [in] igi il
202 in #NAME? um [um], [mɛʧʰ] zum
203 with հետ het [hɛt] ri
204 and և, ու ev, u [jɛv], [u]
205 if եթե et'e [jɛtʰɛ] ud
206 because որովհետև orovhetev [voɾovhɛˈtɛv]
207 name անուն anun [ɑˈnun] mu
и чем больше языков предложат свои варианты - тем лучше, а правильность информации уж как-нибудь проверим.
До сих пор это не удалось никому.